我們可以用很多第三方程式去擷取OpenStreetMap的圖資,但是地理範圍較大的資料容量也很大。若直接匯入QGIS不僅浪費資源也影響程式穩定度,宜在Python用命令列做預處理。
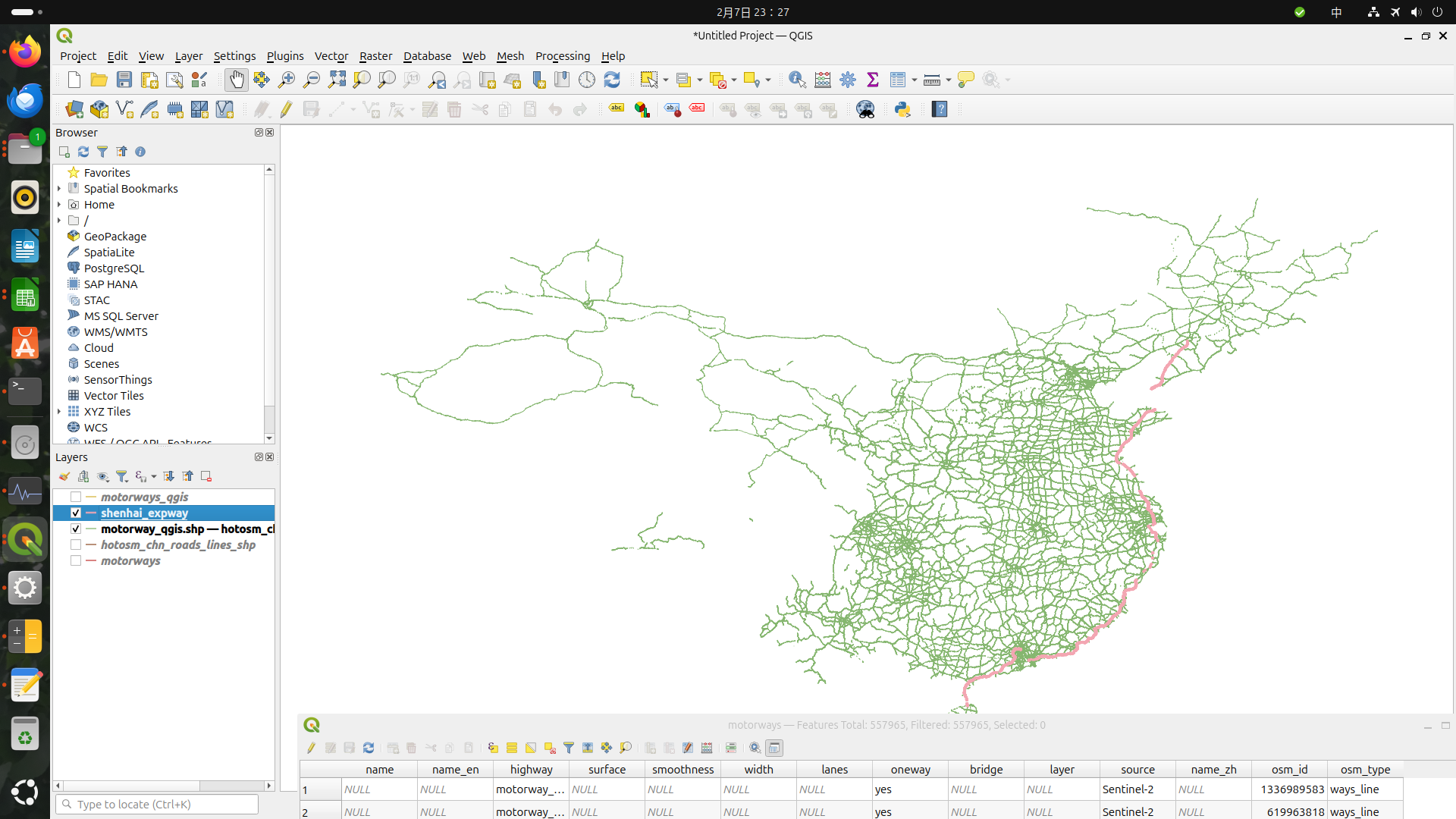
用極端點的例子,我想製作中國的高速公路網圖,可以在人道救援資料集找到擷取OSM中國所有道路的資料集,你再從中篩選出高速公路資料集即可。說來容易,但是檔案抓下來就1.8GB,直接匯入QGIS是不會當掉,但是快七百萬個Features是要等到天荒地老?
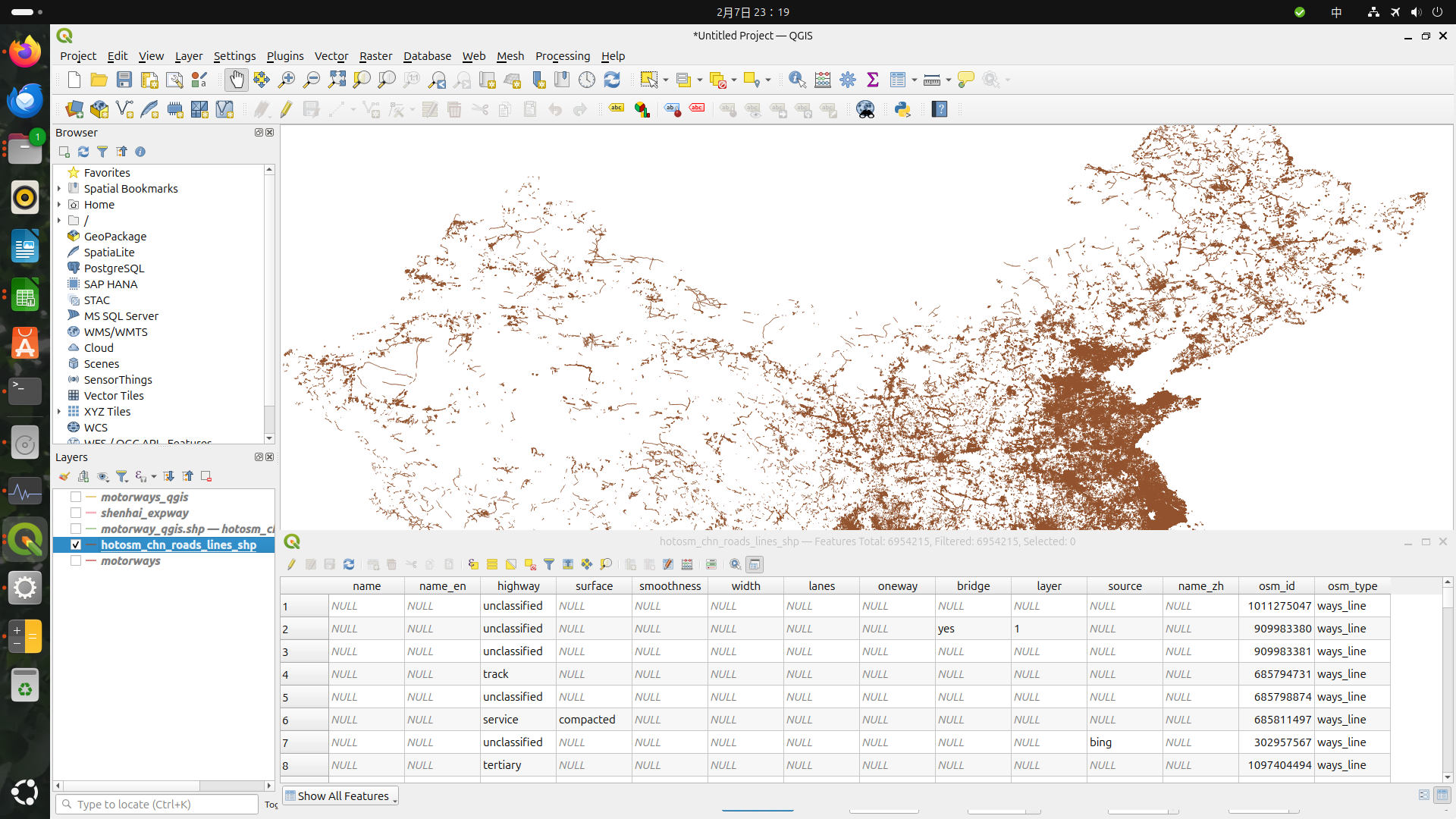
若用Python先做預處理,把資料篩選到約56萬筆再匯入QGIS,事情顯然就簡單得多。拜AI之賜,Google很快就能給你基礎的語法下去修。
基本操作和Pandas非常像,我要知道中國的高速公路在OpenStreetMap是"Highway"的哪個Attribute
我就隨機找一條高速公路,然後知道它應該叫做motorway
我可以再用unique()功能,先挑出各種關鍵字(以及知道有motorway_link,技術上應該是高速公路的聯絡線,有點像我國的國道3甲)
這樣您再用pandas的篩選功能,就能把屬於高速公路和聯絡線的圖資挑出來。以後就不用再讀那麼大的檔案了。
這些語法也可以在我的Github上找到。
import geopandas as gpd
#import pandas as pd
gdf = gpd.read_file("/home/fattabby/下載/hotosm_chn_roads_lines_shp/hotosm_chn_roads_lines_shp.shp")#make an example
#yygs=gdf[gdf["name"]=="甬莞高速"] #我要知道中國的高速在公路等級(英文)是哪種類別
#road_ext=set(gdf["highway"].unique()) #motorway, motorway_link
motorways = gdf[(gdf['highway'] == 'motorway') | (gdf['highway'] == 'motorway_link')]motorways.to_file("/home/fattabby/下載/motorways.shp")
如此便省事多了
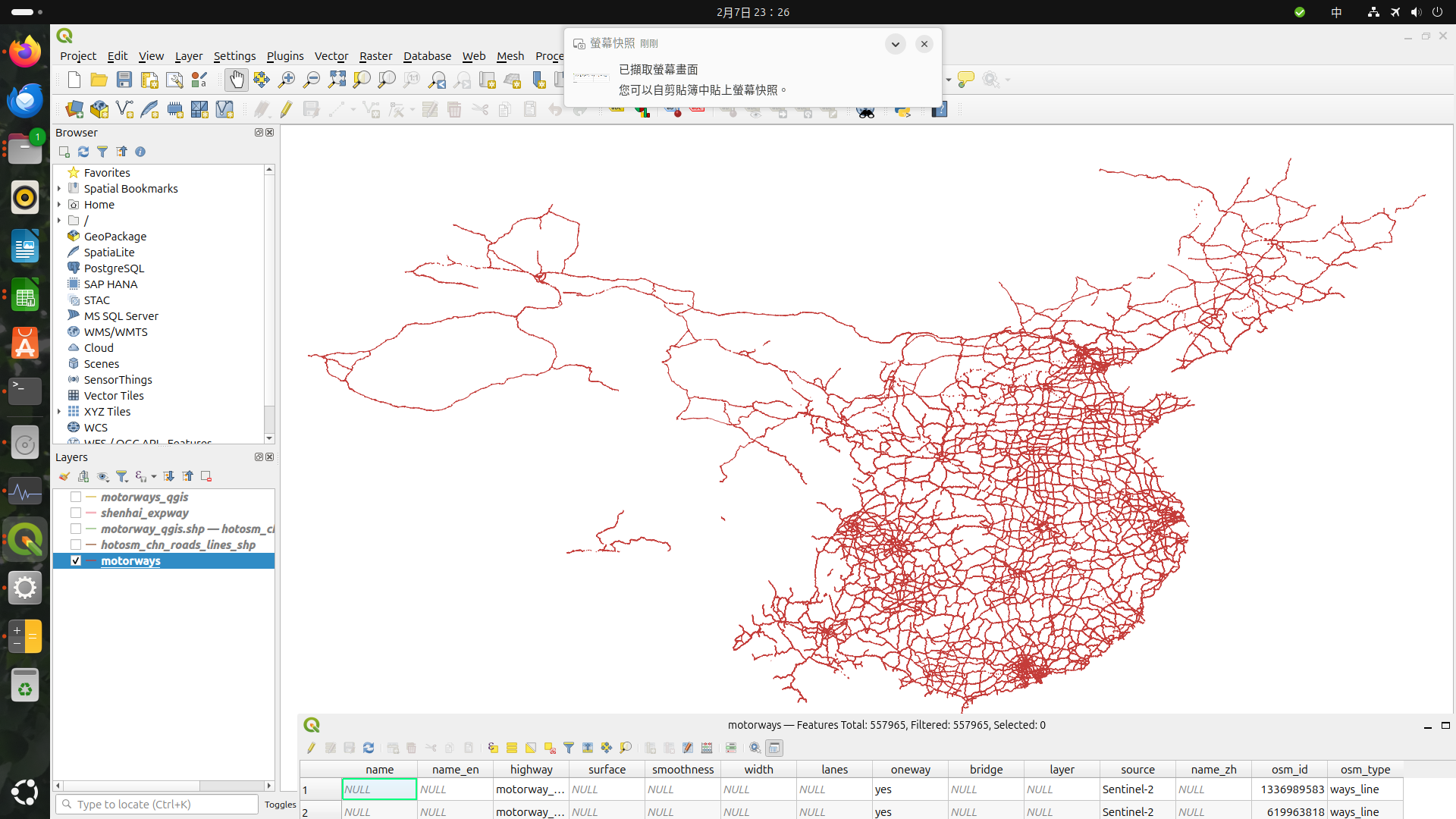
不過這作法也並非毫無缺點,例如當我再進一步篩選出瀋海高速的路型時,卻可發現沿海許多路段出現空缺的情形。仔細看了一下資料,有可能是編輯者在OpenStreetMap的命名方式不統一,造成很多資料不是被誤殺,就是根本沒標注成是高速公路的一部分。這還是得用domain knowledge拆解每個個案,才知道該怎麼處理。