地理資訊系統其中一個有趣的應用,就是取得各路段的高度表。這種高度表在爬山、修築鐵公路時非常重要。雖然這次文章的標題叫做路段,但我想用在自然地理上的另一個地方,即河川(從源頭)到入海口大致的高度表。這在水利資源開發,例如航道規劃、水庫設計都有他的工程需求。
資料來源
雖然我國政府資料有河川河道的開放資料,提供了非常詳細的行水區的面(polygon)資料。但是高度表需要的是線段資料,把面轉成線的步驟也非常繁瑣。因此我這次使用的是第三方Geofabrik從OpenStreetMap弄下來的台灣圖資。但我這次決定不用以前常用的Shapefile格式,而是較罕見的pbf格式。
雖然Geofabrik抓下來的Shapefile檔案,編排與格式都符合一般人在GIS的日常習慣,但是它把很多河川上下游的關係的資料都去掉了。這樣在釐清上下游水系和支流的關係時會非常麻煩。
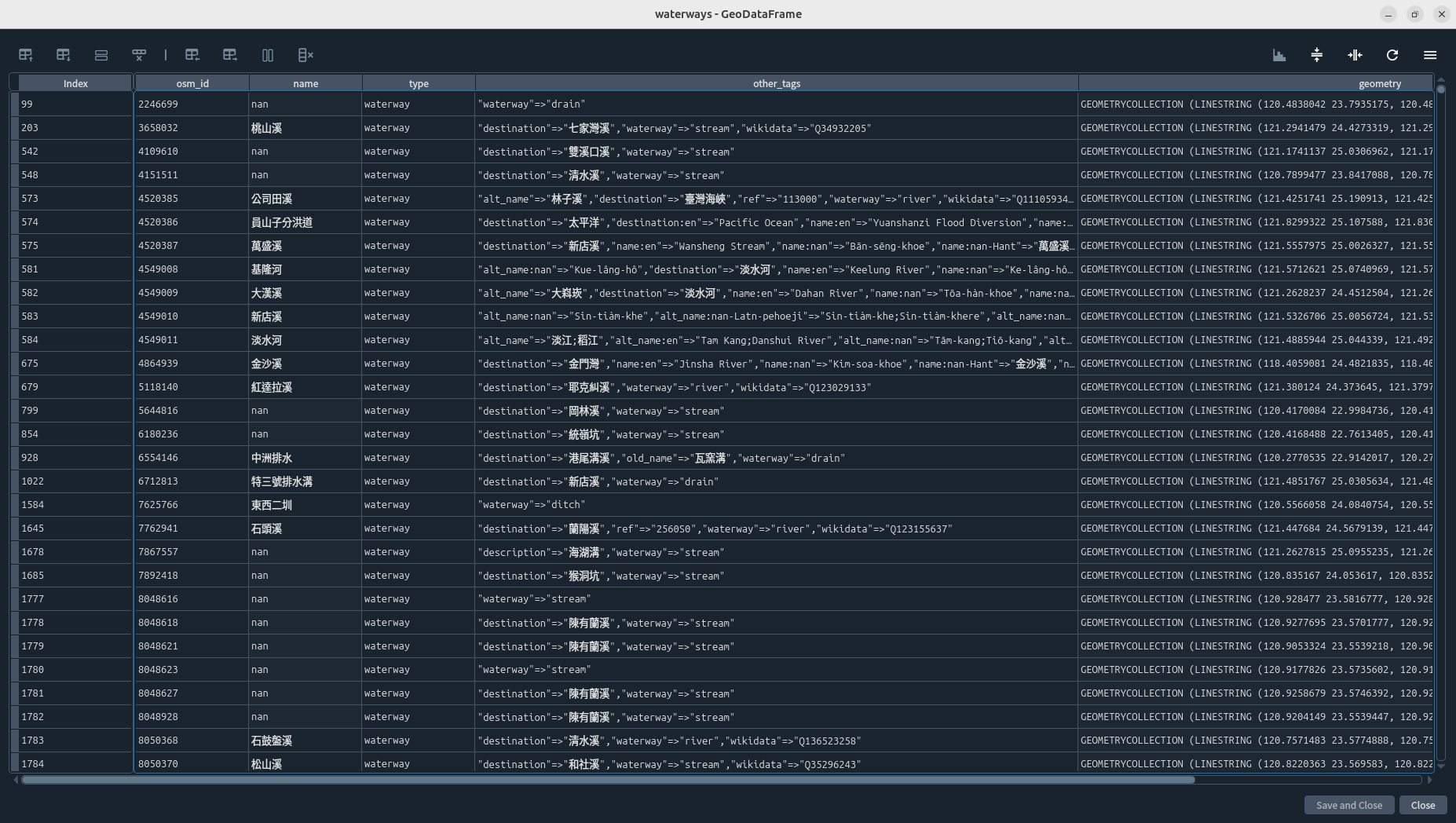
反觀pbf雖然一開始稍微醜了一點,但是在other_tags欄位卻完整保留了水系之間的關係。接下來我會說明怎麼處理(完整語法請參見)。
讀取pbf檔案
讀取pbf檔案的方式和shapefile大同小異,但是因為pbf裡的東西太多了,系統會顯示以下警告訊息:
UserWarning: More than one layer found in 'taiwan-260221.osm.pbf': 'points' (default), 'lines', 'multilinestrings', 'multipolygons', 'other_relations'. Specify layer parameter to avoid this warning.
因此您要加一個layer參數,本次使用的是"other_relations":
taiwan_all_others=gpd.read_file("/home/fattabby/下載/taiwan-260221.osm.pbf",layer = "other_relations")
我看過有文章(但一時忘記出處)建議您連engine和use_arrow都加參數。實測上是還沒發現不加就給您少出一筆資料的狀況,端看個人意願。
taiwan_all_others2=gpd.read_file("/home/fattabby/下載/taiwan-260221.osm.pbf",engine="pyogrio", use_arrow=True,layer = "other_relations")
假設你要處理淡水河的資料
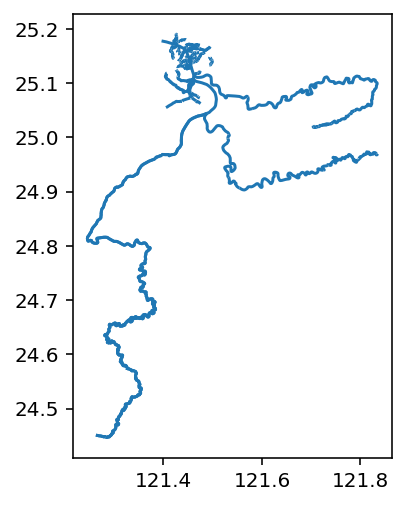
若我想看整個淡水河水系長什麼樣子,可以用以下語法抓資料,並做圖看看是否合乎預期:
danshui_river=waterways[(waterways["other_tags"].str.contains('淡水河'))]
danshui_river.plot() #預覽
這樣,我們看到的大漢溪、新店溪、和基隆河,以及下游應該是關渡那一帶,許多人繪製的水圳之類的水道。整體來看符合我們對淡水河的認知。
假設你要一口氣處理多個水系的資料
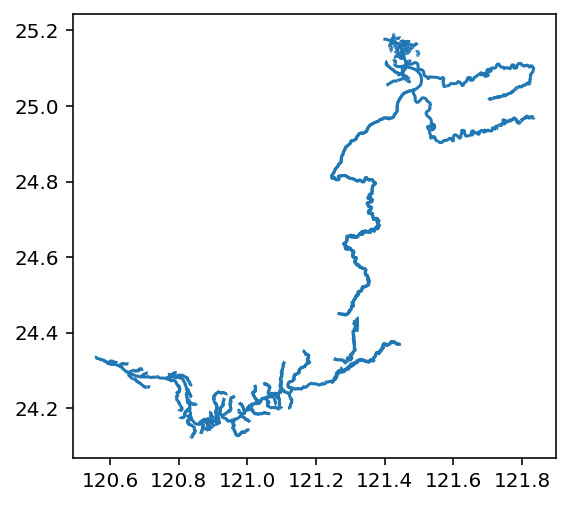
假設我同時要處理淡水河和大甲溪的資料,可以用類似pandas的功能,用以下的方式把多筆資料餵給它和做圖。但是這裡別自己改成用list餵給它,系統會報錯:
danshui_dajia_river_remix=waterways[(waterways["other_tags"].str.contains('淡水河|大甲溪',regex=True))]
danshui_dajia_river_remix.plot() #預覽
您可以看一下製圖結果,是不太好讀,但也沒有太離譜。但是可能因為貢獻者的多寡差異,所以大甲溪的部份就不如淡水和下游那麼詳細。
製作高度表相關資料
處理淡水河幹流
接下來為了方便,我只用淡水河的幹流來演示。我使用isin的參數,確定名字裡只有淡水河的線段會被納入資料。但是使用list餵進去預留新增條件的空間。
danshui_river_main2=waterways[waterways['name'].isin(['淡水河'])]
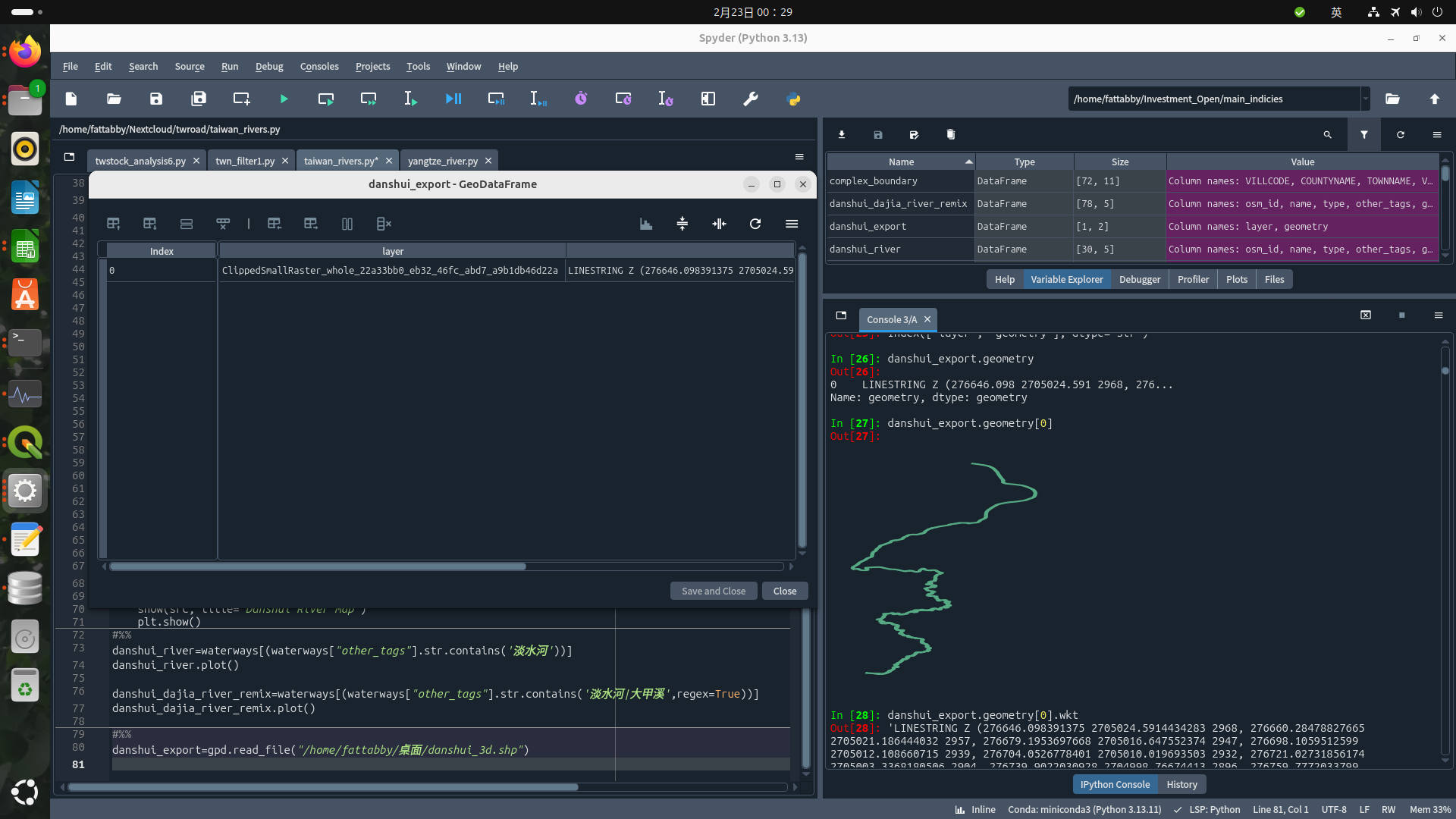
因為shapefile不支援GEOMETRYCOLLECTION的物件型別,所以要把GEOMETRYCOLLECTION(語法請參考這裡)做轉換
danshui_river_main2["geometries"] = danshui_river_main2.apply(lambda x: [g for g in x.geometry.geoms], axis=1)
danshui_river_main2 = danshui_river_main2.explode(column="geometries").drop(columns="geometry").set_geometry("geometries").rename_geometry("geometry")
除了物件轉換之外,還要給定和轉換shapefile的地圖投影才能順利存檔
danshui_river_main2=danshui_river_main2.set_crs(epsg=4326) #原始資料是WGS84
danshui_river_main2=danshui_river_main2.to_crs(3826) #我要把它轉成TWD97,在台灣的景物測距離用TWD97比較好danshui_river_main2.to_file("/home/fattabby/下載/danshui_main.shp")
處理淡水河途經行政區
雖然我國的內政部20公尺網格數值地形模型資料不大,但是考慮運算的效率與經濟,僅需節選淡水河流經的行政區的地形圖(本次精確至村里界)。
twn_boundary=gpd.read_file("/home/fattabby/Nextcloud/twroad/villages/VILLAGE_NLSC_11401031.shp")
twn_boundary=twn_boundary.to_crs(3826)
river_passedby = gpd.clip(twn_boundary, danshui_river_main2)
river_passedby=river_passedby.VILLCODE.to_list()
complex_boundary=twn_boundary[twn_boundary["VILLCODE"].isin(river_passedby)]
complex_boundary.to_file("/home/fattabby/Nextcloud/twroad/river_passedby.shp")
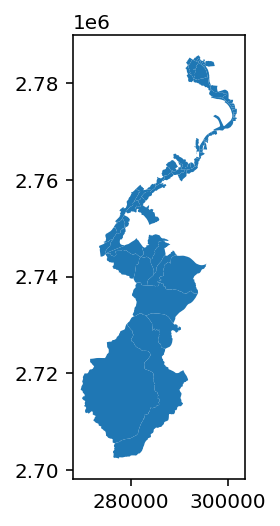
這樣便可找出淡水河流經的里,並將這些里合併成一張圖。需要注意的是,為避免村里可能撞名的問題,這裡是用資料裡的唯獨碼VILLCODE來串接。
完成後也再作圖確定結果是否合乎預期,因為這裡我已經改成TWD97座標,所以顯示的不是常見的經緯度:
套疊地形圖
明明這些步驟可以在QGIS內搞定,為何要捨近求遠打命令列,還要花掉許多查語法的時間呢?這是考量:
- 效能與經濟性:台灣的地域小,資料也不算多,普通電腦尚可勝任。但是遇到美國、中國這種大國的資料,大批資料匯入QGIS不但慢,而且容易灌爆記憶體,而需要事先在命令列預處理。且用pandas的unique()方法可以在極短時間內知道這欄位裡有哪些東西。
- 步驟的可複製性:很多地圖不是做一次就好,而是頻繁更新。若只會用圖形化介面,每次有資料更新就可能要點滑鼠到抓狂。
- 流程的標準化:圖形化介面操作容易隨著各人偏好順序和習慣的不同,造成結果不一甚至疏漏的情形。打命令列可以標準化流程,有問題查bug也比較容易。
這點在處理圖形資料就特別重要了。
#code source https://gis.stackexchange.com/questions/444062/clipping-raster-geotiff-with-a-vector-shapefile-in-python
import rasterio
from rasterio.mask import mask
#import geopandas as gpdinshp = "/home/fattabby/Nextcloud/twroad/river_passedby.shp"
inRas = '/home/fattabby//Nextcloud/twroad/不分幅_全台及澎湖DEM/dem_20m.tif'
outRas = '/home/fattabby//Nextcloud/twroad/不分幅_全台及澎湖DEM/ClippedSmallRaster_whole.tif'Vector=gpd.read_file(inshp)
#Vector=Vector[Vector['HYBAS_ID']==6060122060] # Subsetting to my AOI
with rasterio.open(inRas) as src:
Vector=Vector.to_crs(src.crs)
# print(Vector.crs)
out_image, out_transform=mask(src,Vector.geometry,crop=True)
out_meta=src.meta.copy() # copy the metadata of the source DEM
out_meta.update({
"driver":"Gtiff",
"height":out_image.shape[1], # height starts with shape[1]
"width":out_image.shape[2], # width starts with shape[2]
"transform":out_transform
})
with rasterio.open(outRas,'w',**out_meta) as dst:
dst.write(out_image)
from rasterio.plot import show
import matplotlib.pyplot as plt
#cf GOOGLE AI
#cf https://help.marine.copernicus.eu/en/articles/5051975-how-to-open-and-visualize-geotiff-files-using-python
# Open the TIFF file
tiff_file_path = '/home/fattabby//Nextcloud/twroad/不分幅_全台及澎湖DEM/ClippedSmallRaster_whole.tif'
with rasterio.open(tiff_file_path) as src:
# Plot the image using rasterio.plot.show()
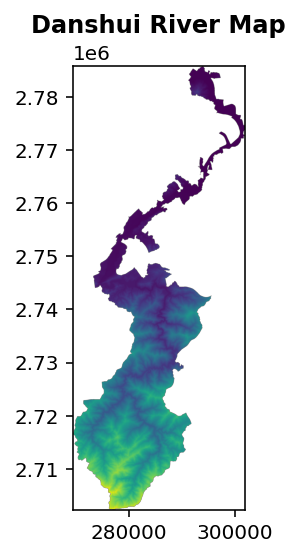
show(src, title="Danshui River Map")
plt.show() #作圖確認結果
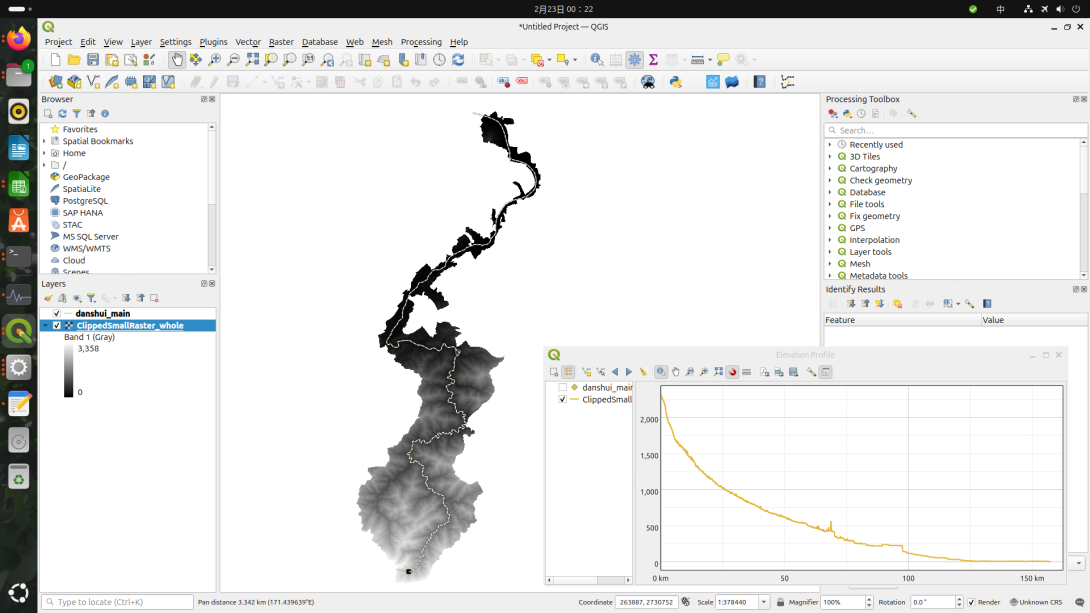
完成後作圖確認,結果大致符合預期。雖然我沒有把河流套疊上去,但是看到上游的地形圖還是不難看出,那些溝谷應該是河流長年侵蝕山體的結果。
回到QGIS套疊地形圖與產製高度表
進入QGIS,把剛才做好的淡水河線形和地形圖匯入後。用前文提到的Join Multiple Lines技巧,將淡水河連成一條完整的線。
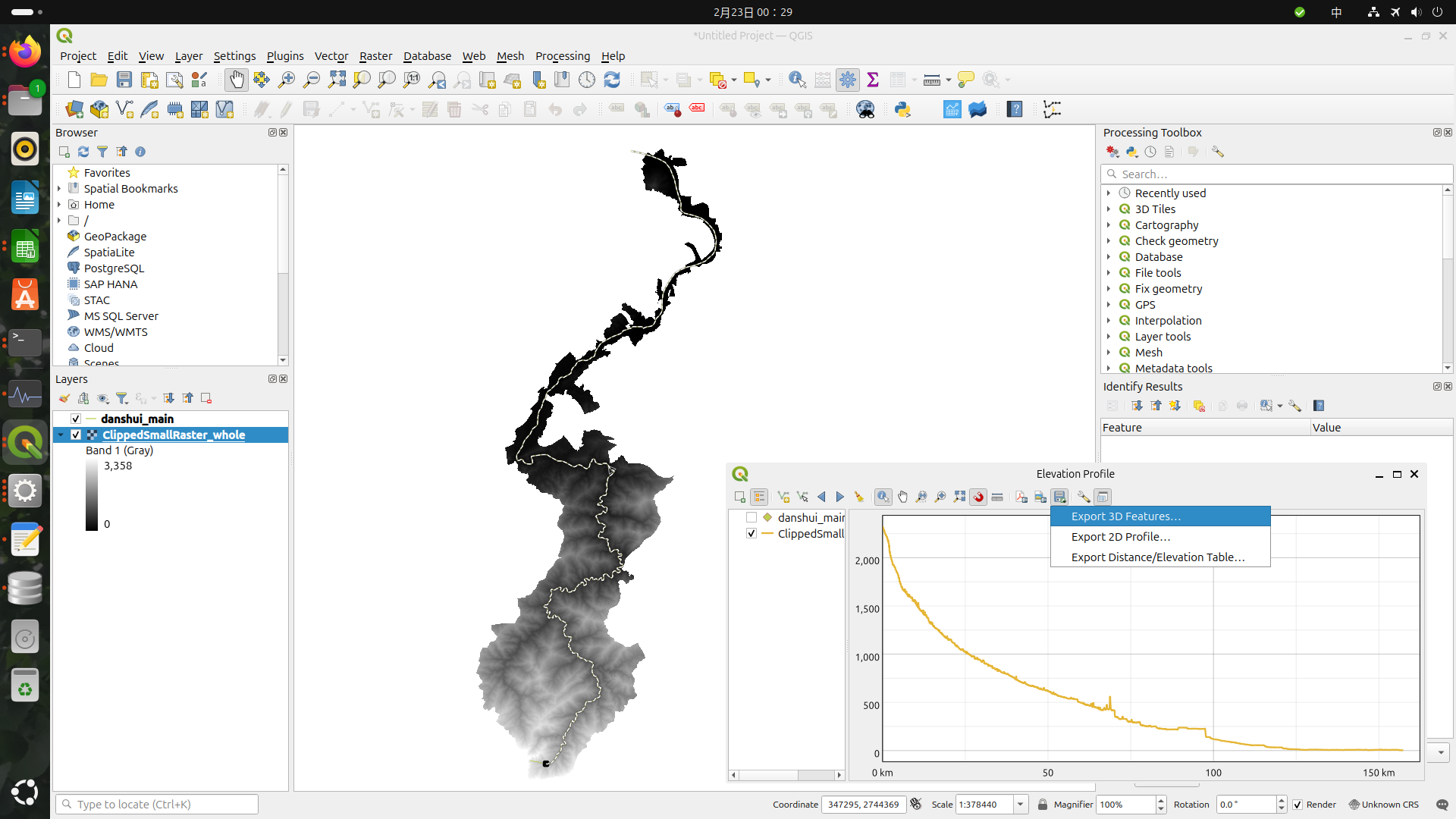
使用View -> Elevation Profile功能。
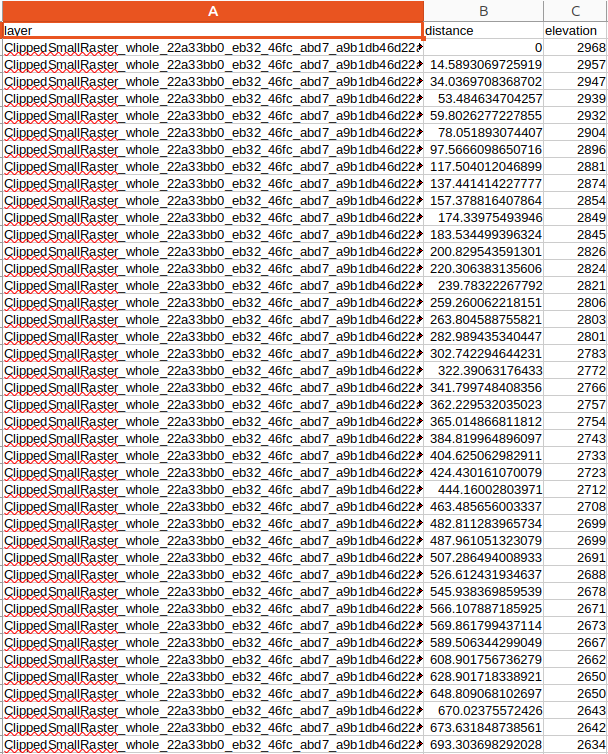
即可做出河流各路段的高度變化表。不過有趣的是,平常是水往下流,有些時候卻往上流了!
具體的原因我不是很清楚,可能是地形取樣誤差,或人工建築例如水壩影響地形造成。大趨勢仍是正確的。
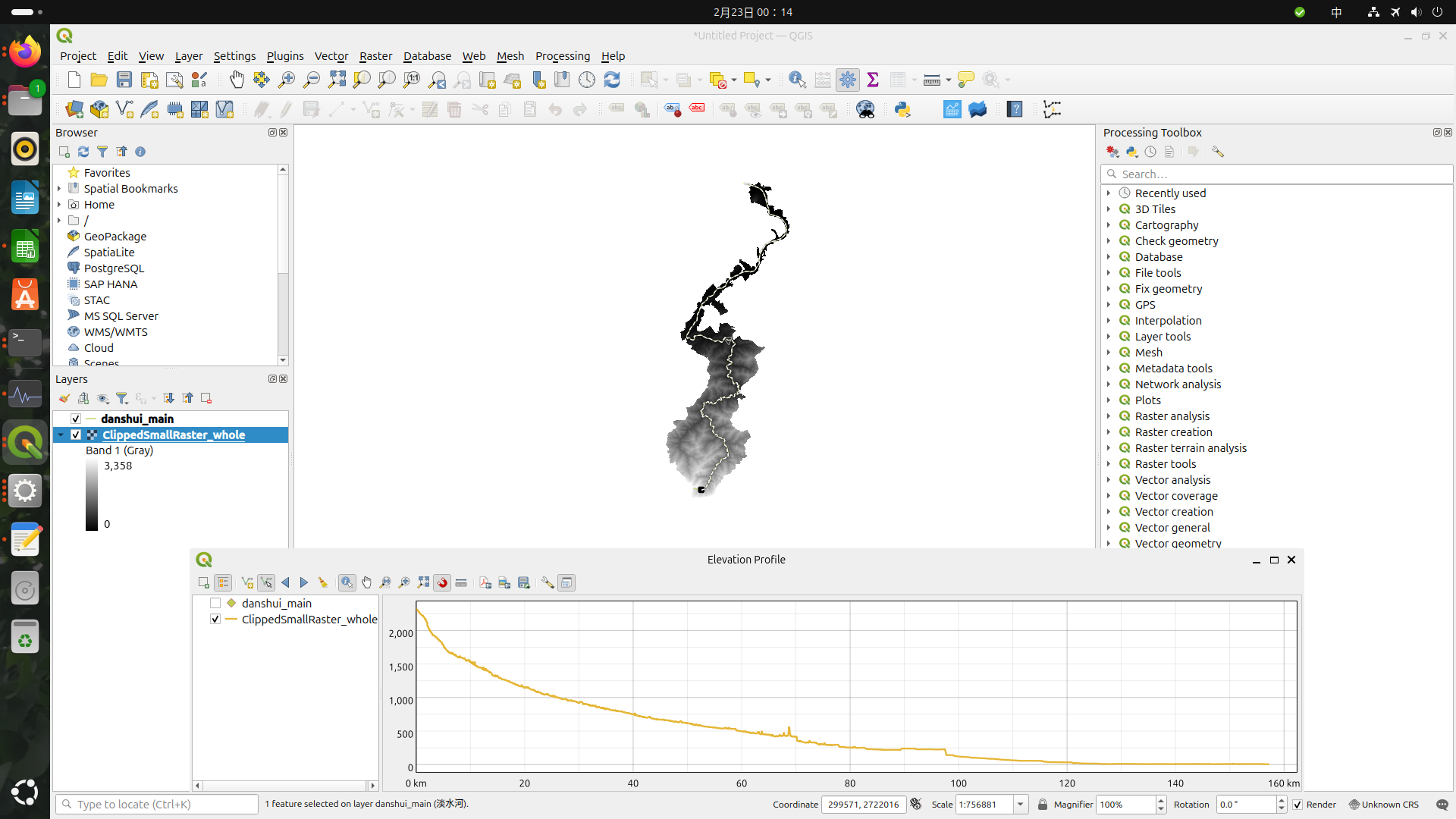
不過個人實測發現,這個Elevation Profile的功能還不算很完整,截稿前還只能出很簡單的報表,告訴你在幾公里處高度是多少之類的。希望以後這功能日後會更加完整。
補充
經實測後發現,若您是把這份資料的3D Feature存成Shapefile的話
是可以在Python用geopandas模組拆解出線段中各點的XYZ座標的。而這種隱藏版功能若要在QGIS裡弄不是找不到,就是操作很繁瑣,都遠不如在Python直接。這都是我後來處理地理資訊,必須加用Python操作的原因。