讀法規考古題,不外乎是要記法條。但是一條一條從全國法規資料庫慢慢複製貼上會很繁瑣。最便捷的方式無非是寫支爬蟲,逐條寫進檔案(本例是csv)。但是請留意,爬蟲請避免用在有著作權或流量限制的網站上以免觸法。在合理使用的前提下,使用政府的開放資料還是比較妥當。(以下語法可至我的Github下載)
以我國刑法為例,進入全國法規資料庫刑法的網頁後,在條文處按右鍵->檢測,我們要看這html文件的階層分佈。知道他的物件Class為"col-no";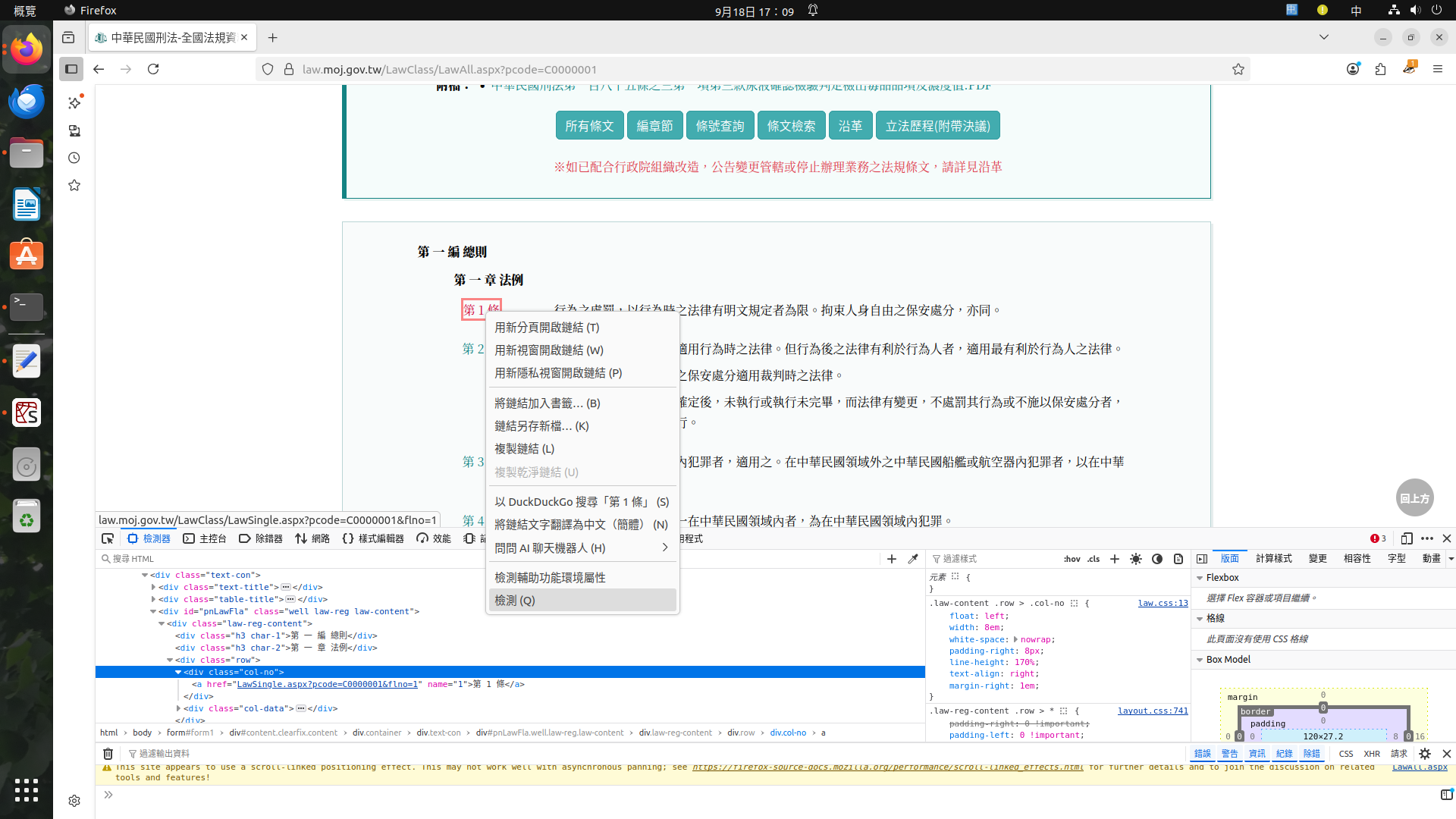
同樣看到內文的物件Class為"law-article"
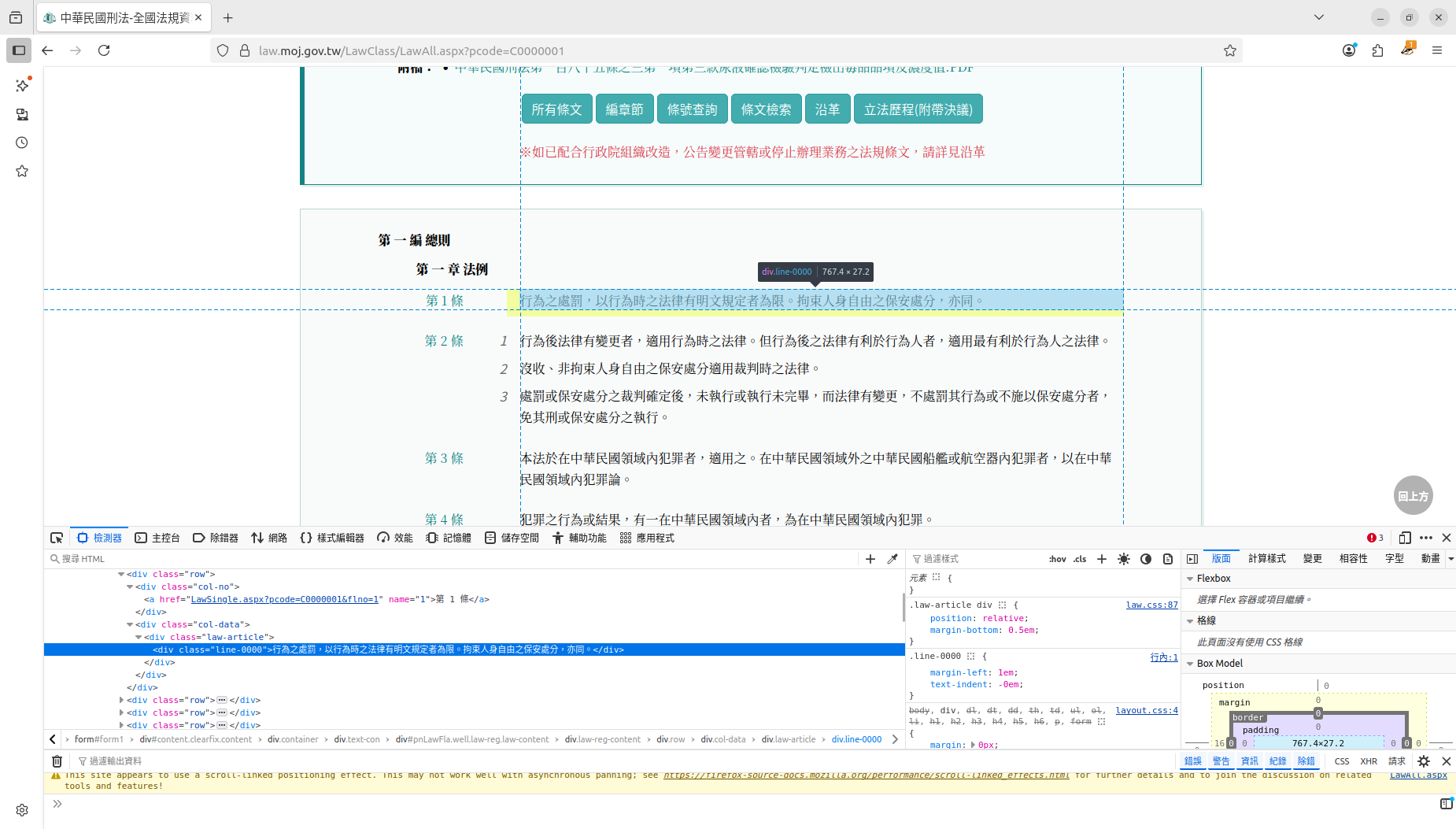
通常他會以一對一的方式出現,如果能用爬蟲工具拆解物件的結構,爬回家就省事多了。
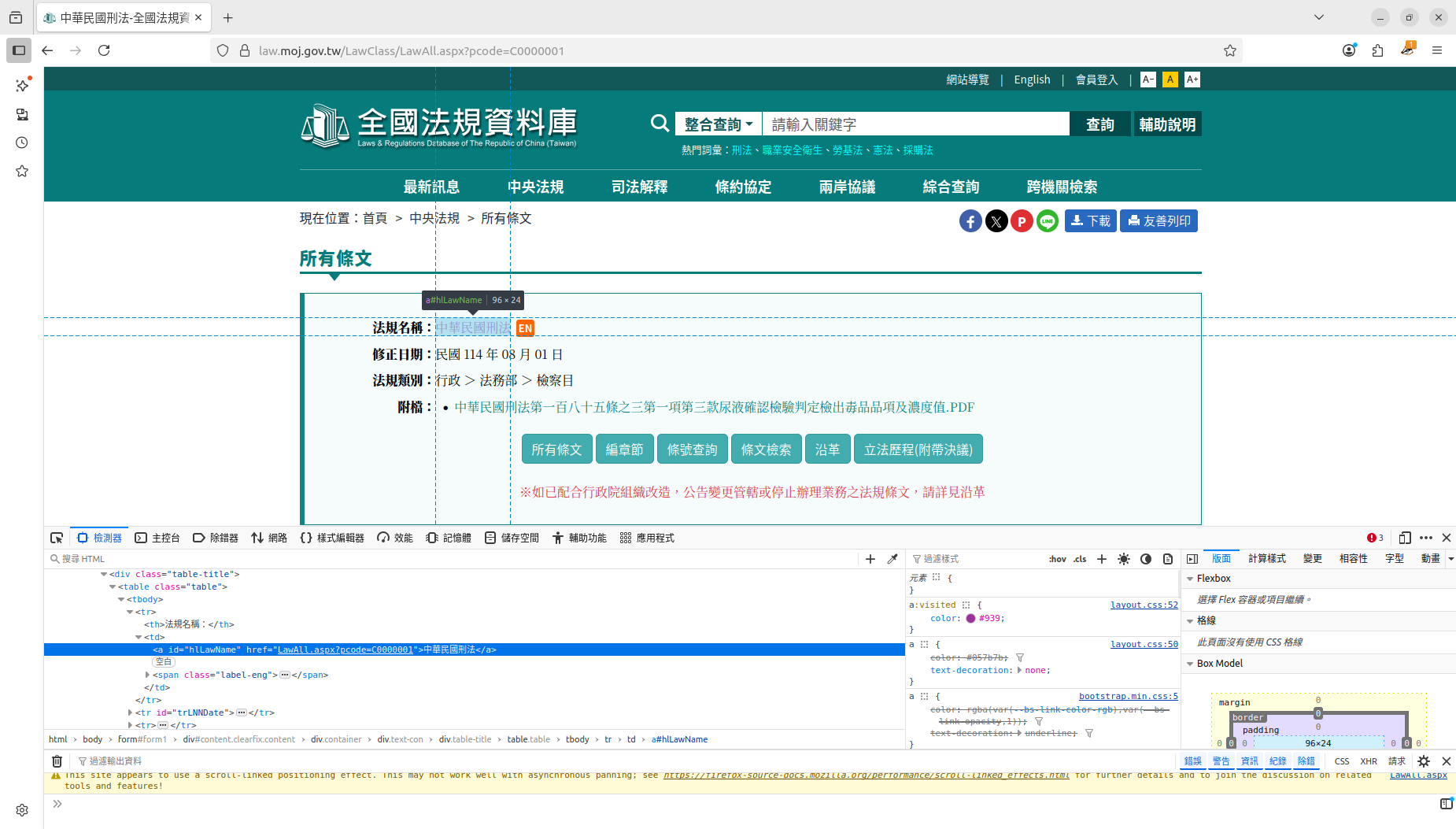
利用同樣的方法,也可以查到法條名稱是在Class "table"的地方,至於後面a什麼的那個是html語法中比較細節的東西,我就不在這詳述。把這名稱存起來,我就不用手動輸入法條名稱。
因此,我寫了一支程式碼長這樣
#我是分隔線
#第一段
import time
import requests
from bs4 import BeautifulSoup
from urllib.parse import unquote
import pandas as pd
database=pd.DataFrame([],columns=["actname","title","article"])
#%%第二段
#urls=[]
url = input('請輸入全國法規資料庫網址:')
web = requests.get(url)
soup = BeautifulSoup(web.text, "html.parser")
filename=soup.find('table').find('a').text
#urls=urls[0:6]
#start_time=time.time()
#print(start_time)
def crawl_questions(url):
web = requests.get(url)
soup = BeautifulSoup(web.text, "html.parser")
#soup.select('p:contains("第 ")')
titles = soup.find_all('div', class_='col-no') # 取得 class 為 title 的 div 內容
#print(titles)
#print(titles.text)
articles=soup.find_all('div', class_='law-article')
#titles_output = []
lawbase=pd.DataFrame([],columns=["actname","title","blank1","blank2","blank3","blank4","blank5","article"])
#articles_output = []
for i,j in zip(titles,articles):
exports=pd.DataFrame([])
exports["actname"]=[filename]
exports["title"]=[i.text.replace(" ", "")]
exports["article"]=j.text.strip()
lawbase=pd.concat([lawbase,exports])
#titles_output.append(i.text)
#articles_output.append(j.text)
return lawbase
lawbase=crawl_questions(url)
database=pd.concat([lawbase,database])
#database.to_csv("{}.csv".format(filename))
#%%第三段
database.to_csv("{}.csv".format(filename),index=False)
#我是分隔線
之所以寫成3段,是因為如果你想爬好幾部法條的時候,你必須只執行第二段程式碼,才不會把上一次爬的法條蓋掉。其實整條Script不分段執行,只爬一部法條也是OK的。
如果正常執行完,理論上能跑出如圖的結果
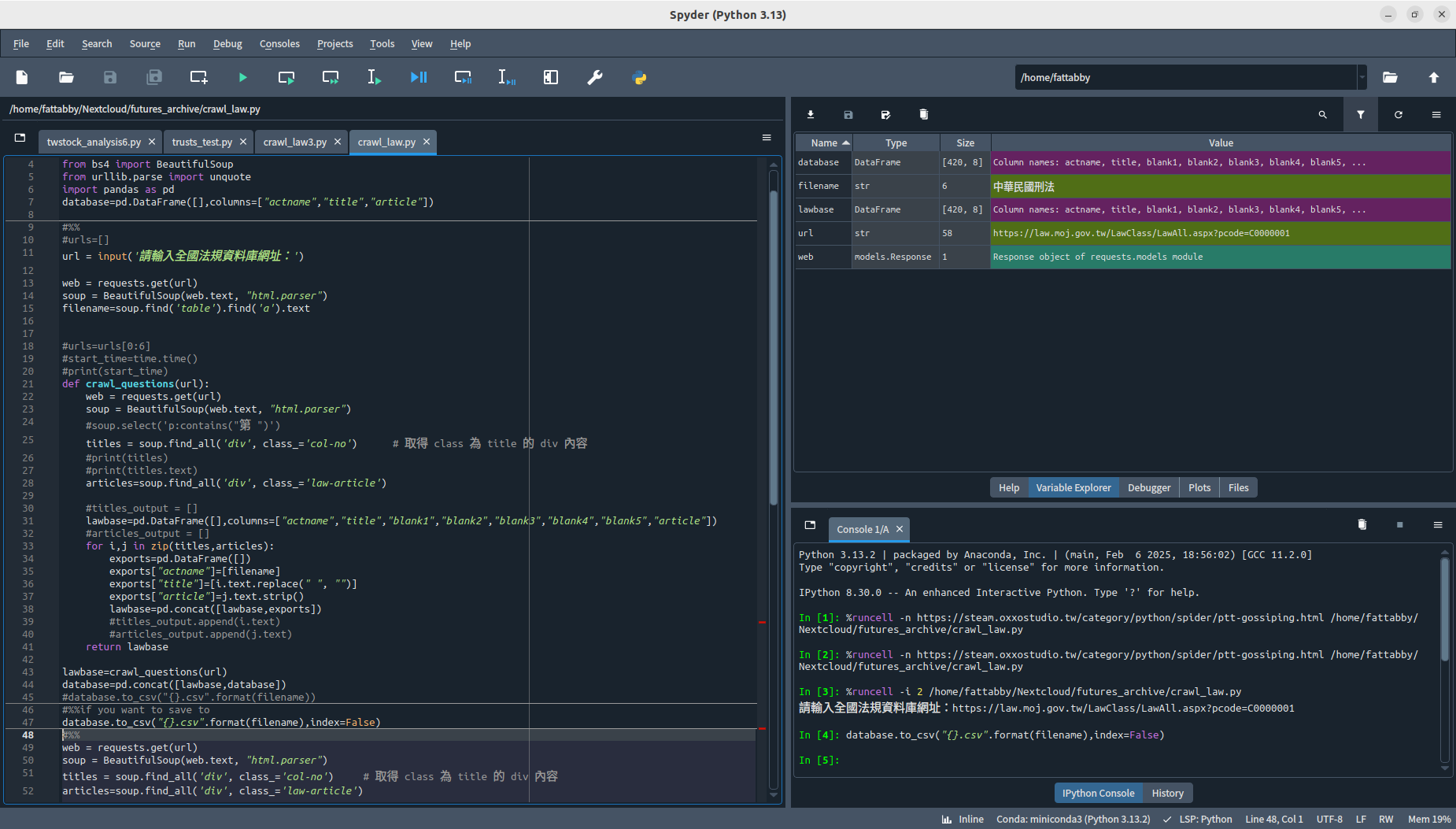
然後在您的工作資料夾(work directory)找到這個檔案:
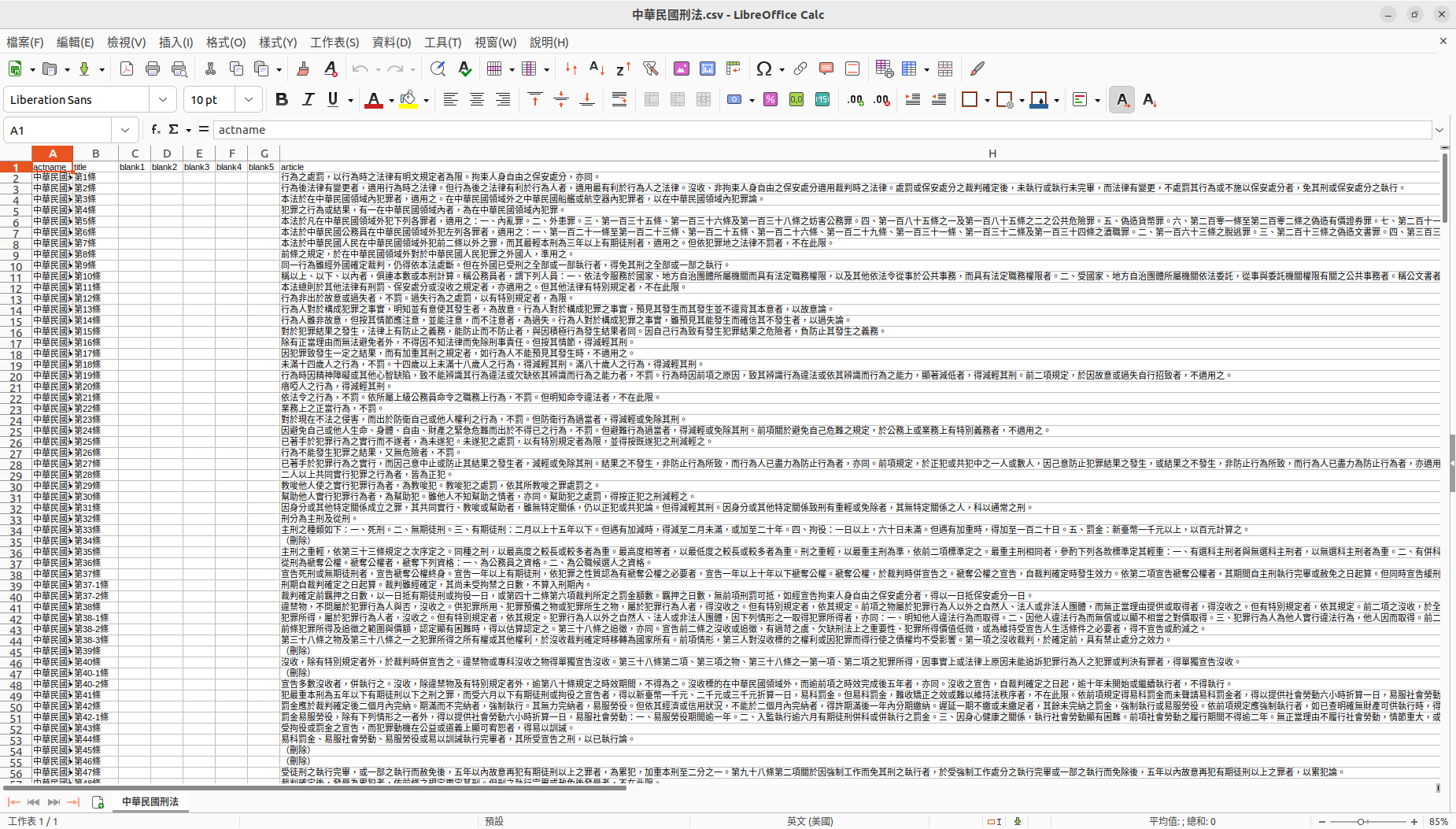
至於要不要留下那麼多空白的Column(欄),端看使用者需求。就請自行在程式第二段裡修改參數。
後記
有人可能會問,爬下來之後到底要做什麼呢?
答案是用另一支程式後製後給Speech Note,做成隨身聽當作床頭音樂啦。這樣眼睛累的時候,還是可以用耳朵來加強記憶,外加助眠效果!!