近期需要從較老舊的圖書館系統匯出想借閱的書目列表,資料結構大概長這樣:
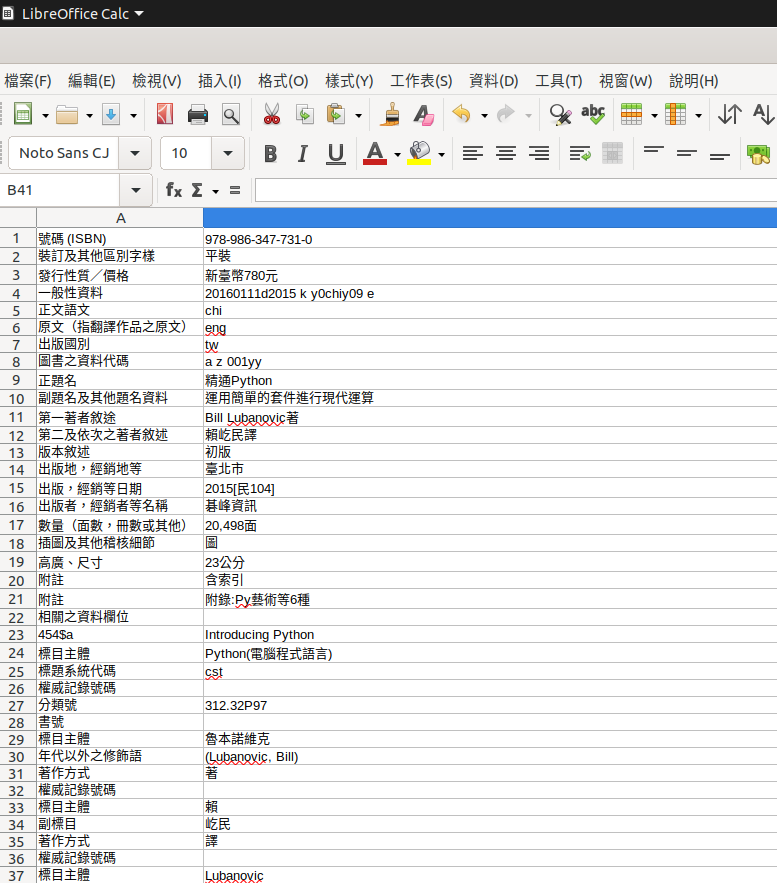 ________________________________________
________________________________________
裝訂及其他區別字樣:平裝
發行性質/價格:新臺幣780元
一般性資料:20160111d2015 k y0chiy09 e
正文語文:chi
......
_________________________________________
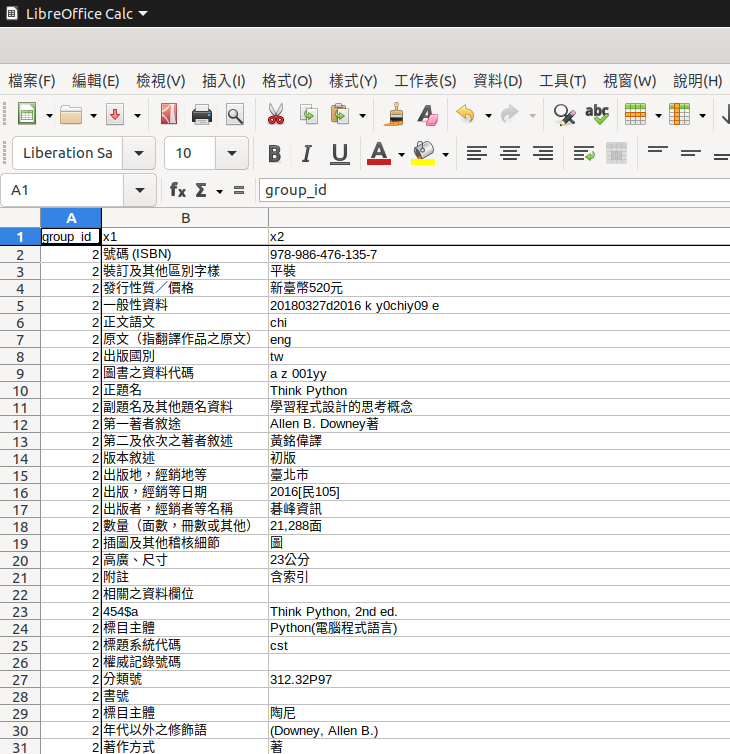
但是上面那樣顯然不是適合人閱讀的報表,也不利後續利用。因此需要整理成如下圖的樣式:

我們當然不想滑鼠一個一個慢慢拉,但是該怎麼辦呢?感謝Facebook上R的討論群網友的救援,在徵得當事人同意分享的情況下,以下將介紹(與適度修改)運用的程式碼(以下為預覽):
library(reshape)
df <- read.csv("您的檔案位置", col.names = c("group_id", "x1", "x2"), encoding = "UTF-8" )
#建議在這階段手動設定編碼,否則可能後續會造成許多不必要問題;是否要手動命名col.names請自行斟酌
df <- df[!is.na(df$group_id), ]
#雖然原作者表示不必跑第2行,但是跑了可以刪除一些空的欄位
df2 <- reshape(df, direction = "wide", idvar="group_id", timevar="x1")
#direction意指將資料展開成水平軸較長的表,idvar意指用哪個欄位分組;timevar在這裡則是你想被整理的欄位(如作者、ISBN...等)
- 資料前處理:
在做資料整併前,您應該先讓系統知道這是哪一本書的資料。所以我們設了一個新變數叫group_id。右邊欄位姑且命名成x1,x2。
再用剛才展示的程式碼下去跑,如果沒意外應該能跑出如下的結果:
(但我習慣把data frame命名為booklist,所以命名會和上面的程式碼略有不同)
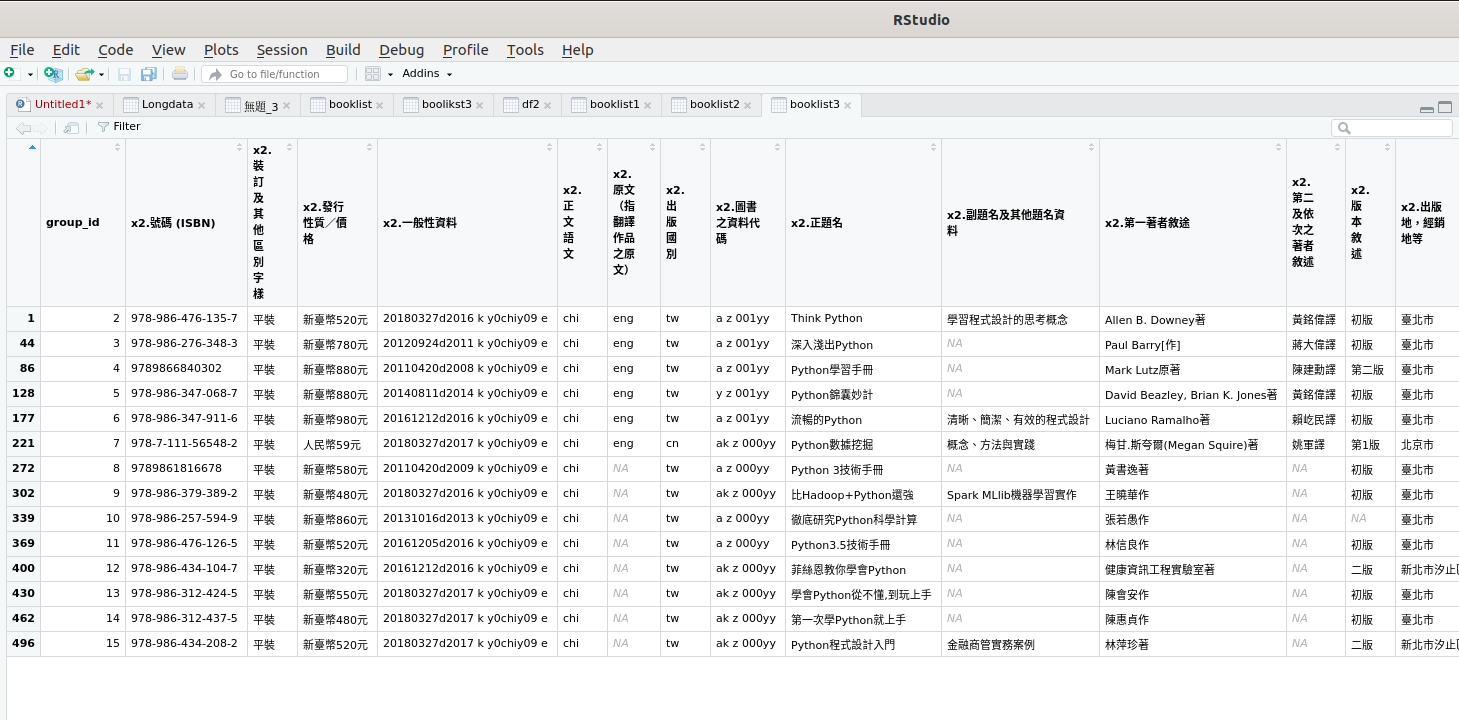
這樣顯然是比自己在Excel或Calc上一個一個點快多了。這方法或可適用於其他結構化資料的爬蟲後處理。